hi,
i’m indexing a really large db table (~4.2 million rows). i’ve noticed
that after ~2M records, index performance decreases by almost an order
of magnitude. full dataset graph here:
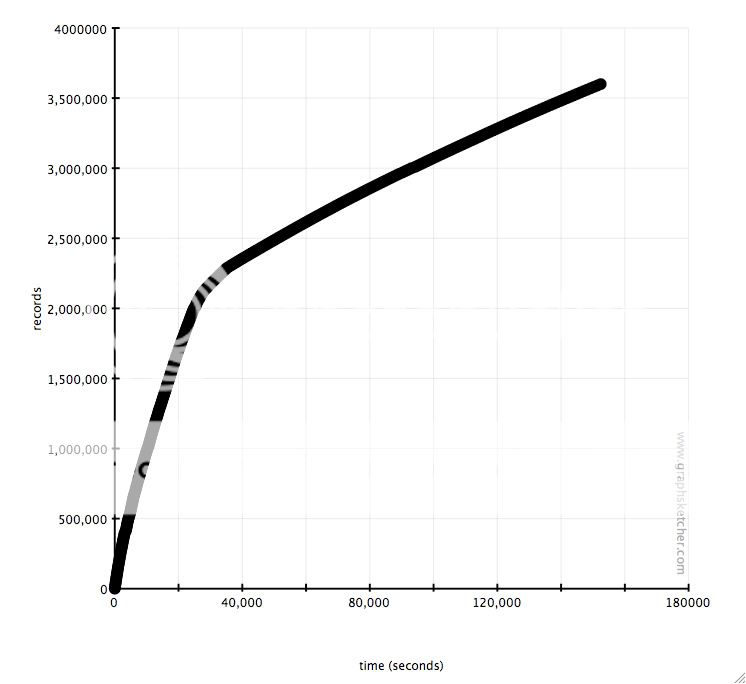
here’s a couple best-fit lines that represent the data points:
0-2M : y = 78.65655x + 144237.5
2.5M+ : y = 10.79832x + 1980630
the part that strikes me as most odd is the bend between 2M and 2.5M. i
haven’t read the ferret algorithm, but i would expect either linear or
hyperbolic performance over time. however, the graph seems to indicate
a particular breaking point after which performance is cut by 8x. is
this behavior normal/expected? is there anything i could be doing to
speed up an index of this size? (the index grows to ~12G while indexing,
then gets shrunk to ~6G by the optimization)
thanks for the help!
-m
— MODEL CODE
class MyModel < ActiveRecord::Base
think of body/title in terms of an average blog
acts_as_ferret :fields => { ‘body’ => {}, ‘title’ => { :boost => 2 } }
end
— INDEX CODE
index =
Ferret::Index::Index.new(MyModel.aaf_configuration[:ferret].dup.update(:auto_flush
=> false, :field_infos => MyModel.aaf_index.field_infos, :create =>
true))
n = 0
BATCH_SIZE = 1000
while true
new index from scratch
records = MyModel.find(:all, :limit => BATCH_SIZE, :offset => n,
:select =>
“id,#{MyModel.aaf_configuration[:ferret_fields].keys.join(‘,’)}”)
break if (!records || records.length == 0)
records.each do |record|
index << record.to_doc # aaf method
end
n += BATCH_SIZE
end
index.flush
index.optimize # 30+ minutes =(
index.close
— CONFIG
gem list | grep ferret
acts_as_ferret (0.4.0)
ferret (0.11.3)
uname -a
Linux gentoo 2.6.20-hardened #3 SMP Fri Mar 30 19:27:10 UTC 2007 x86_64
Intel(R) Pentium(R) D CPU 3.00GHz GenuineIntel GNU/Linux